アクセスインターフェース - Chapter 3 Disk and File Management
ディスクドライブの記事で述べたとおり、HDD や SSD のデータはハードウェアレベルでは セクタ 単位でアクセスされます。セクタサイズは通常 512 bytes や 4 KB です。
ディスクごとにセクタサイズやアドレス指定方法は異なるため、OS はその詳細をアプリケーションから隠し、ディスクへのシンプルなアクセスインターフェースを提供します。
ブロックレベルインターフェース
ブロック は、ファイルシステムの基本的な論理単位です。OS がデータを管理する際の最小単位で、1 つ以上のセクタから構成されます。
ブロックとセクタはマッピングされており、それぞれのブロックには ブロック番号 が付与されており、ブロック番号からセクタのアドレスを特定できます。
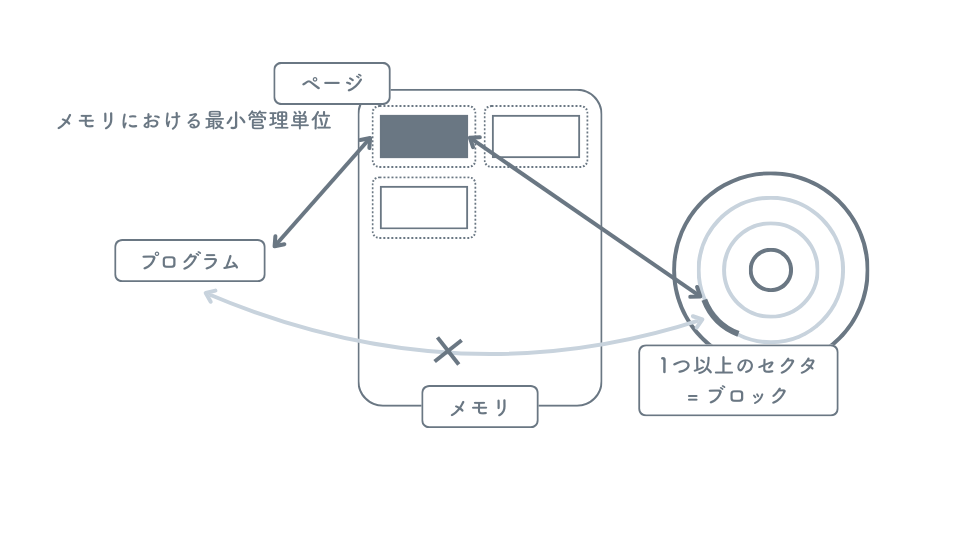
ディスクへのデータアクセスの際は、ディスク上のデータを直接操作するのではなくブロックを構成するセクタをメモリの ページ に読み込んでからアクセスします。
ページとブロック
ページ は仮想メモリや DBMS におけるメモリ上のデータ管理の最小単位です。バッファプールやキャッシュの文脈で使われます。一方、ブロック はより低レイヤのディスクレベルでのデータの読み書きの単位を指し、ディスク I/O やファイルシステムの文脈で使われます。 通常、I/O の管理単位としてページとブロックは 1:1 で対応しており、ページ ≒ ブロックとして扱われることが多いようです。
ファイルレベルインターフェース
ファイル は、OS が提供するデータの論理的な単位で、ファイルは、1 つ以上のブロックから構成されます。クライアントからはブロックの詳細は隠蔽され、ファイルを通じてデータにアクセスします。
特定のファイル位置に対応する実際のディスクブロックを決定する流れは、論理ブロック参照 -> 物理ブロック参照 の 2 段階で行われます。
1. 論理ブロック参照 (Logical Block Reference)
指定されたバイト位置を相対的なファイル内のブロック番号に変換します。
例えば、ブロックサイズが 4096 bytes の場合、バイト位置が 7992 のデータはファイルの第 2 ブロックに格納されていることになります。
2. 物理ブロック参照 (Physical Block Reference)
実際のディスクブロックの位置を特定します。後述のファイルシステムの実装方法に依存するため、1 つ目の変換より複雑です。
連続配置 (Continuous Allocation)
各ファイルを連続するブロックの並びとして保存する方法です。ファイルがディスクブロック b から始まるならば、ファイルのブロック N はディスクブロック b + N にあります。
この方式には 2 つの欠点があります。
- ファイルのすぐ後ろに他のファイルが有ると、そのファイルを拡張できない
- 最大ブロック数を見積もってファイルを作成すると、結果として未使用のブロック (内部フラグメンテーション) が生じる
- ディスクを使用するにつれ空きブロックが断片として残る
- トータルとして十分な容量の空きブロックがあっても、散在しているため (外部フラグメンテーション)、連続した大きな領域が確保できない
エクステントベース配置 (Extent-Based Allocation)
ファイルを固定長の エクステント (extent) に分割し、各エクステントを連続するブロックの並びとして保存します。ファイルシステムのディレクトリには、各ファイルについてすべてのエクステントの先頭ブロックのリストが記録されます。
固定のエクステント長でデータが保存されるので、内部および外部フラグメンテーションを削減することができます。
ファイルが X ブロックごとにエクステントを保存する場合、ブロック N は、エクステント番号 N / X の先頭ブロック + (N mod X) で特定されます。
例えば 8 ブロックごとにエクステントを保存する場合、ファイルの 21 番目のブロックは 21/8 = 2 で、エクステントリストの 3 番目のエクステントの先頭ブロック + (21 mod 8) = 5 になります。
エクステントリストより 3 番目のエクステントの先頭ブロックが 696 と特定された場合、ブロックの実際の位置は 696 + 5 = 701 です。
インデックス配置 (Indexed Allocation)
この方式では、ファイル内の各ブロックを 1 ブロックずつ個別に割り当て(要はエクステント長が 1 ブロック)。
さらに、インデックスブロック (index block; ib) を用意し、ファイルの各ブロックが格納されているディスク上のブロック番号をリストとして記録します。ib[N] はそのファイルの論理ブロック N が格納されているディスクブロック番号です。
ブロックが 1 つずつ割り当てられるため、フラグメンテーションが発生しません。一方で、1 つのインデックスブロックが保持できるブロック番号の数だけしかブロックを割り当てられないため、ファイルの最大サイズに制限があります。
古典的な Unix File System(UFS)や ext 系ファイルシステム(ext2, ext3, ext4 など)はこの戦略をベースにしています。
ただし、シンプルな一次インデックスだけではなく、階層(多層)構造を使い、ファイルサイズ制限の問題に対応しています (c.f. inode pointer structure)。
ブロックレベルインターフェースとファイルレベルインターフェースの違い
OS はブロックレベルとファイルレベル両方のインターフェースを提供します。2 つのインターフェースの違いをまとめると以下のようになります。
| 項目 | ブロックレベルインターフェース | ファイルレベルインターフェース |
|---|---|---|
| アクセス単位 | ブロック (ページ) | ファイル |
| 制御の自由度 | 高い | 低い |
| 利点 | 高速化のための最適化が可能 | 実装が簡単/ファイルシステムの機能が利用できる |
| 欠点 | 実装が複雑/ファイルシステムの機能が利用できない | 高速化のための最適化が難しい/OS による余計な I/O が入る可能性あり |
データベースシステムは ファイル単位でストレージを管理しつつ、そのファイルをページ (ブロック) 単位に分けて管理 する戦略をとっています。
具体的には、テーブルやインデックスなどをデータファイルとして保持し、 open() や write() などのシステムコールでファイル操作します。そして「ページ番号 N 番の位置をオフセット計算して読み込む」といったように、DBMS 側で定義したページサイズ単位でデータを読み書きします。
データベースシステムは完全にディスクを制御できるわけではありませんが、ディスクアクセスに対してかなりの制御を維持することができます。